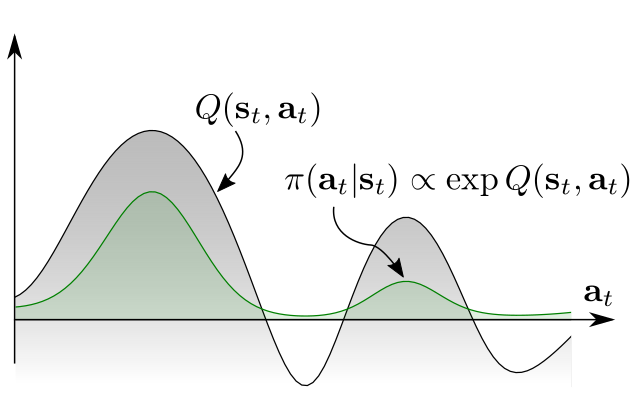
 Equivalence between Policy Gradients and Soft Q-Learning
Equivalence between Policy Gradients and Soft Q-Learning
Inspecting the gradients of entropy-augmented policy updates to show their equivalence
Equivalence between Policy Gradients and Soft Q-Learning
Inspecting the gradients of entropy-augmented policy updates to show their equivalence
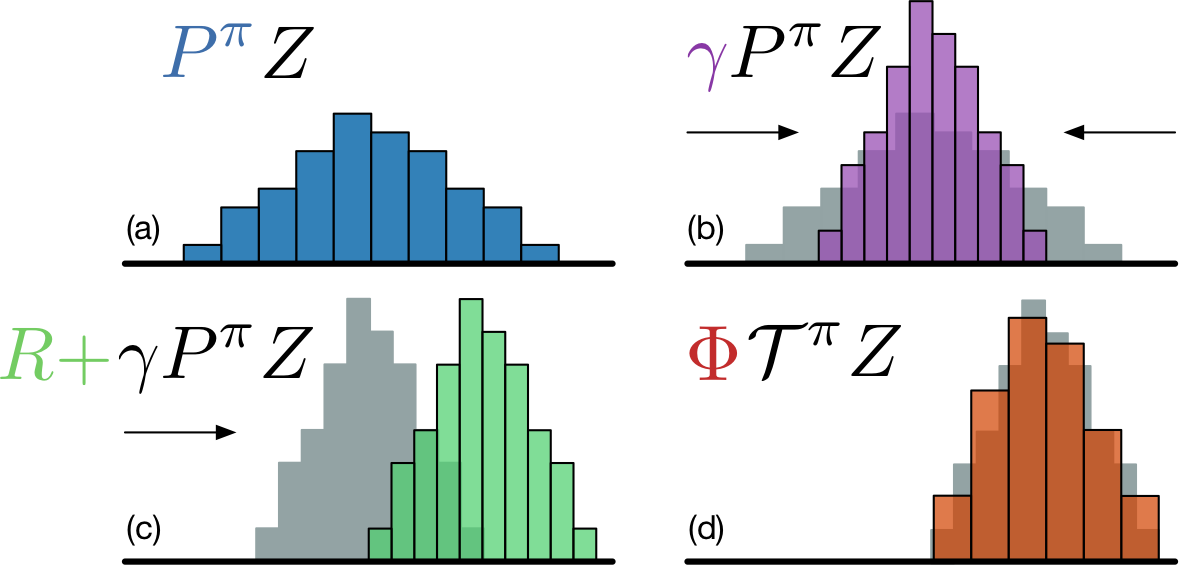 Distributional Deep Q-Learning
Distributional Deep Q-Learning
Expanding DQN to produce estimates of return distributions, and an exploration into why this helps learning
The purpose statement and introduction to Computable AI.