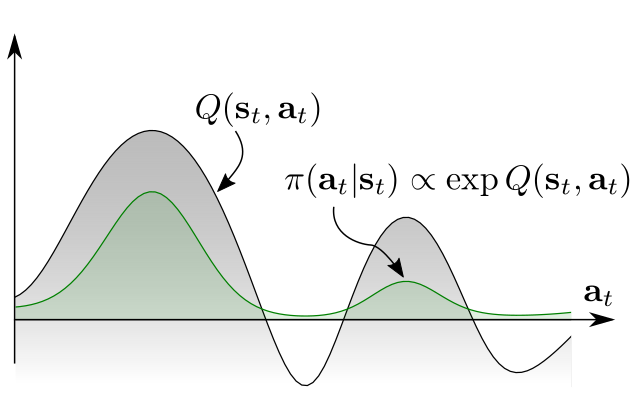
 Equivalence between Policy Gradients and Soft Q-Learning
Equivalence between Policy Gradients and Soft Q-Learning
Inspecting the gradients of entropy-augmented policy updates to show their equivalence
Equivalence between Policy Gradients and Soft Q-Learning
Inspecting the gradients of entropy-augmented policy updates to show their equivalence
 Three Method Comparison for Traffic Signal Control
Three Method Comparison for Traffic Signal Control
Comparing supervised learning, random search, and deep reinforcement learning on traffic signal control.
Learning Compound and Composable Policies
Straightforward hierarchical RL for concurrent discovery of sub-policies and their controller.
Efficient exploration with self-imitation learning
I wonder if that happens every time...
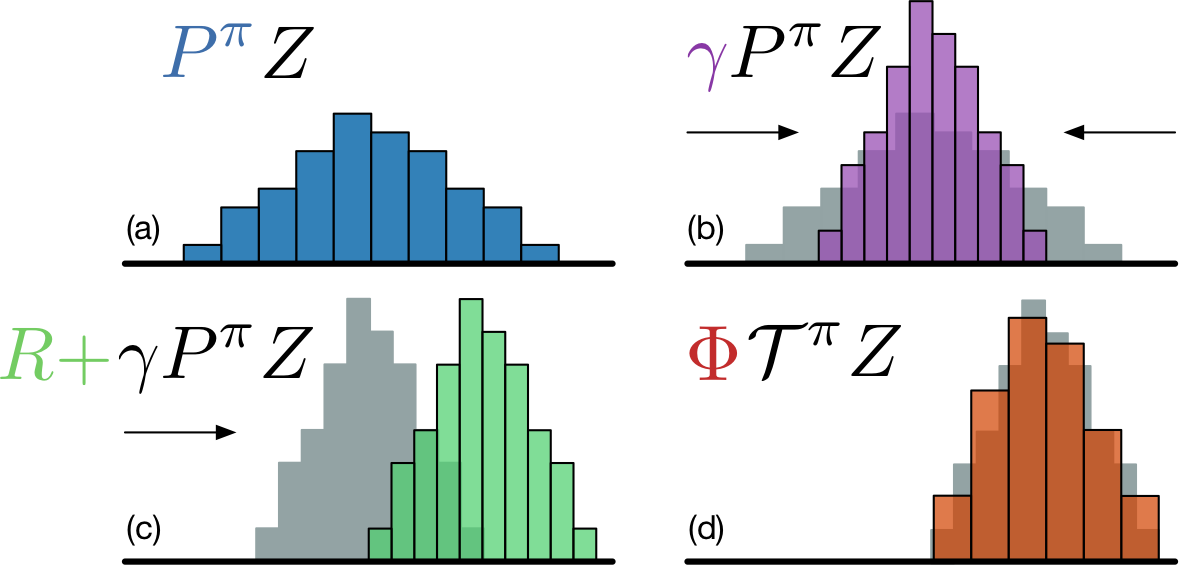 Distributional Deep Q-Learning
Distributional Deep Q-Learning
Expanding DQN to produce estimates of return distributions, and an exploration into why this helps learning
Keeping to the Narrow Path
Better imitation learning with self-correcting policies by negative sampling.
 Look at This: Where We See Shapes, AI Sees Textures
Look at This: Where We See Shapes, AI Sees Textures
CNNs trained in "the usual way" tend to learn something different than you might expect. They learn to recognize textures (local structure) rather than shapes (global structure).
Way Off-Policy Batch DRL
Pre-training using a generative model of pre-recorded trajectories and bias correction.
A New Series arXiv Sampler
Beginning a new series highlighting a few interesting RL papers on the arXiv each week. This week: Simple curriculum learning, learning to interact with humans, and warm starting RL with propositional logic.
 Boltzmann Machines: Differentiation Work
Boltzmann Machines: Differentiation Work
My differentiation work while reading Ilya Sutskever on the biological plausibility of Boltzmann machines.